
Torch多GPU训练
Published:
本文主要介绍如何在Torch框架下使用多个 GPU 训练模型,以及通过修改cunn的源码,解决不能充分利用 GPU 显存的问题。
多GPU训练
Data vs. Model Parallelism
通常,使用多个 GPU 加载模型有两种模式,一种是模型并行( Model Parallelism ),另一种是数据并行( Data Parallelism )。
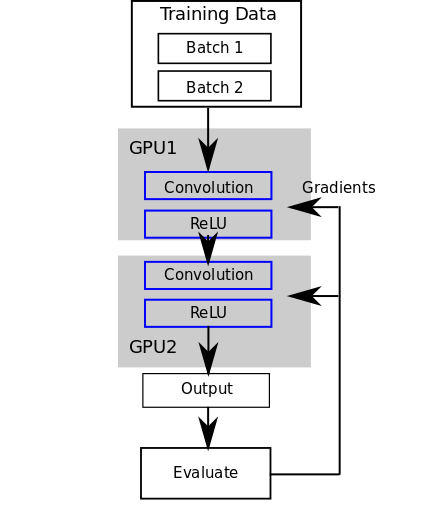
在模型并行的模式下,一个 model 被分成多个部分加载到 GPU 里面,forward的时候,数据流根据模型结点的顺序,从不同的 GPU 中流过。
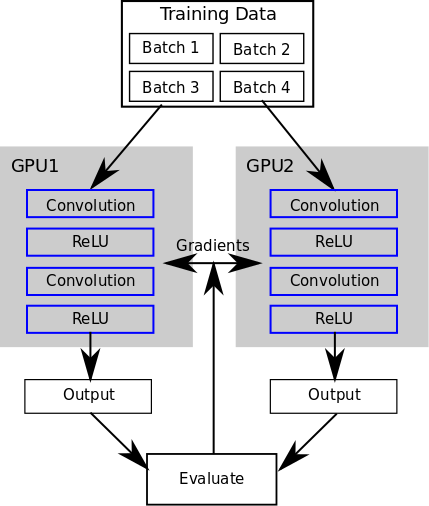
在数据并行的模式下,每个 GPU 都加载一个完整的 model ,但运行不同的 batch 数据。
不同的模式下, GPU 使用的同步方式也不同。数据并行需要同步模型的参数,模型并行需要同步每个块的输入输出。
Torch Example
我们通常需要使用大的batch来训练,因此更常用到Data Parallelism的模式。在Torch下,通过DataParallelTable来实现。示例如下,此函数把模型加载到多个GPU里。
function makeDPT(model, nGPU)
if nGPU > 1 then
print('==> Converting module to nn.DataParallelTable')
assert(nGPU <= cutorch.getDeviceCount(), 'number of GPUs less than nGPU specified')
local GPUs = torch.range(1, nGPU):totable()
local fastest, benchmark = cudnn.fastest, cudnn.benchmark
local dpt = nn.DataParallelTable(1, true, true)
:add(model, GPUs)
:threads(function()
local cudnn = require 'cudnn'
local nngraph = require 'nngraph'
cudnn.fastest, cudnn.benchmark = fastest, benchmark
end)
dpt.gradInput = nil
model = dpt:cuda()
end
return model
end
训练完毕后,我们只需要从其中一个GPU里把模型提取出来即可。
function cleanDPT(module)
return module:get(1)
end
显存利用不足
DataParallelTable内部会有一个中心结点,来调度其他 GPU 的数据和模型。因此,即使每个 GPU 平均分配同样的 batch 大小,第一个 GPU 占用的显存还是会比其他 GPU 多。而且,并行的 GPU 越多,占用的显存越多。举个例子,当我使用8张卡来训练时,开的 batch 大小为32,这样DataParallelTable内部会平均分配,每个 GPU 运行的 batch 为4。正常来说,单卡运行 4 batch 是11G的显存,刚好把卡占满。然而,由于中心结点会占用更多,所以程序会报显存不足的错。
如果减少 batch 为30,DataParallelTable会分配6张卡(包括中心结点)运行4个,剩下两张卡运行3个 batch,还是显存不足,直到中心结点运行3个 batch。但这样,总的 batch 就只能是24,除了中心结点,其余的卡的内存都不能占满,造成了浪费。
可以通过修改cunn的源码,自己配置 batch 的分配方式,解决这个问题。
DataParallelTable内部机制
先通过self:_distribute(self.inputGpu, input)函数,把输入数据分配到 GPU 上。然后每个 GPU 分别运行。随后,通过self.output = self:_concat(self.output, self.outputGpu)函数,收集所有 GPU 上的输出。
因此,我们需要修改的就是这两个函数。文件路径在torch/install/share/lua/5.1/cunn/DataParallelTable.lua.
distribute()
此函数中,只需要替换sliceRange(srcsize, idx, n)函数,此函数输入srcsize为 batch 大小,idx为需要分配的 GPU 序号,n为可用 GPU 总数。返回两个值,index分配 batch 的起始位置,size分配 batch 的大小。只需要在 batch 数量减少时,优先减少中心结点所分配的大小即可。
concat()
此函数根据_distribute()来决定是否需要修改。目标函数是_concatTensorRecursive中的dst:narrow(self.dimension, start, sz):copy(s),根据sliceRange(),修改此处的start和sz即可。